Taking data protection into account in data collection and management
The development of an artificial intelligence system requires rigorous management and monitoring of training data. The CNIL details how data protection principles relate to training data management.
Once the data and its sources are identified, the AI system provider must implement the collection and create its dataset. To this end, it is necessary to incorporate the principles of privacy by design from.

Collection
The collection of data is accompanied by various checks and procedures depending on the modalities and sources of data. Technically, the aim is to ensure that the data collected is relevant in view of the objectives pursued, and thus to ensure compliance with the principle of minimisation.
Collection of data by web scraping
If the data controller re-uses publicly accessible data extracted from websites with web scraping tools, it must in particular ensure that the data collection is minimised, in particular by trying to:
- limit data collection to freely accessible data;
- define, prior to the implementation, precise collection criteria;
- ensure collection of relevant data only and deletion of irrelevant data immediately after its collection or as soon as it is identified as such (when this identification is not possible at the time of the collection).
Data cleaning, data identification and privacy by design
Data cleaning
Data cleaning helps in creating a quality training dataset. This is a crucial step that strengthens data integrity and relevance by reducing inconsistencies, as well as the cost of training. Specifically, it consists in:
- correcting empty values;
- detecting outliers;
- correcting errors;
- eliminating duplicates;
- deleting unnecessary fields;
- etc.
Identification of relevant data
The selection of relevant data and characteristics is a classic procedure in the field of AI. It aims to optimise the performance of the system while avoiding under- and over-fitting. In practice, it ensures that certain classes that are unnecessary for the task are not represented, that the proportions between the different classes are well balanced, etc. This procedure also aims to identify data that is not relevant for training. Data identified as irrelevant will then have to be deleted from the dataset.
In practice, this selection can be applied to three types of objects constituting the dataset:
- The data: these may be ‘raw’, unstructured data (audio extract, image, handwritten text file, etc.) or structured (measures, observations, etc. in digital format);
- The associated metadata: literally “data on data”, metadata provide information about the collection process (what was the acquisition process? by whom was it carried out? when? etc.), the format of the data (how should they be exploited?) or its quality;
- The annotations and characteristics extracted from the data (or features): descriptions attributed to the data in the case of annotations, or measurable properties extracted from the data for the characteristics (information relating to the shape or texture of an image, the pitch of sounds, the timbre or tempo of an audio file, etc.).
Several approaches can contribute to the implementation of this selection. The following is illustrative:
- The use of techniques and tools to identify the relevant characteristics (feature selection), sometimes prior to training. Principal Component Analysis (PCA) can also help identifying highly correlated characteristics of a dataset and thus retaining only those that are relevant. Many libraries such as Yellowbrick, Leave One Feature Out (LOFO) and Facets today offer implementations for selecting features.
- The use of interactive data annotation approaches such as active learning, which allows the user to review data performing the intended task and, where appropriate, to delete those that are not relevant. The Scikit-ActiveML library is an example of this.
- The use of data/dataset pruning techniques: this technique, discussed in several publications such as Sorscher et al., 2022 or Yang et al., 2023, reduces the computation time required for training without significant impact on the performance of the model obtained, while identifying data that is not useful for training.
Finally, in certain specific cases where the storage of data may be complex or problematic (due to the sensitivity of the data, issues related to intellectual property, etc.), the principle of minimisation can be implemented by the exclusive storage of the extracted characteristics and the deletion of the source data from which they originate.
Privacy by design
Furthermore, in addition to these necessary steps, the provider of the AI system must implement a series of measures to integrate the principles of privacy by design.
They must take into account the state of knowledge, their impact on the effectiveness of the training, the costs of implementation and the nature, scope, context and purposes of the processing, and the risks (of which the likelihood and severity vary) of the processing for the rights and freedoms of individuals. These measures may include:
- Generalisation measures: those measures are intended to generalise, or dilute, the attributes of the persons concerned by changing their respective scale or order of magnitude;
- Randomisation measures: these measures aim to add noise to the data in order to decrease its accuracy and weaken the link between the data and the individual.
These measures must be implemented on the data and the associated metadata.
In some cases, these measures may extend to the anonymisation of the data, in particular if the purpose does not require the processing of personal data. If data selection and management qualify as processing of personal data subject to the GDPR (and thus to these how-to sheets), further processing will no longer be affected by the regulations on the protection of personal data.
For more information on these measures, see Opinion 05/2014 on G29 anonymisation techniques.
In addition, some measures, such as differential privacy or federated learning, protect data when training the AI system,. Although some of these techniques are still at the research stage, tools can be used to test their effectiveness, such as PyDP or OpenDP.
For Data
The measures depend on the categories of data concerned and must be considered in terms of their influence on the technical – theoretical and operational – performance of the system. The impact of these measures is particularly beneficial due to:
- on the one hand, their ability to reduce the consequences of a possible privacy leakage (by compromising the data contained in the dataset, or by an attack on the trained model such as a membership inference attack);
- on the other hand, the possibility of using the model in the operational phase on data subject to the same protection measures, thus offering the ability to better protect them in the operational phase.
For metadata
Metadata may contain information that is useful to an attacker seeking to re-identify the data subjects (such as a date or place of data collection). The principle of minimisation also applies to such data and should therefore be limited to what is necessary.
For example, metadata may be required by the provider to respond to a request for the exercise of rights, as it sometimes identifies data relating to an individual. In this case, special attention should be paid to their safety.
However, if the processing of metadata is not necessary and it contains personal data, its deletion may be recommended for the purpose of pseudonymisation or anonymisation of the dataset.
Monitoring and updating
Although data minimisation and data protection measures have been implemented during data collection, these measures may become obsolete over time. The data collected could lose their exact, relevant, adequate and limited character, in particular because of:
- a possible data drift under real conditions, that is, a discrepancy between the distribution of training data and the distribution of data under conditions of use. Data drift can have multiple causes:
- upstream process changes, such as the replacement of a sensor, the calibration of which differs slightly from that previously installed;
- data quality problems, e.g. a broken sensor that would always indicate a zero value;
- the natural drift of the data, such as the variation in average temperature over the seasons;
- the appearance of a new category in a classification problem;
- drift due to sudden changes, such as the loss of a system’s ability to detect faces following the massive wearing of masks during the Covid-19 outbreak;
- changes in the relationship between characteristics;
- malicious poisoning as part of continuous learning, which can for example be noticed by abnormal outcomes.
- upstream process changes, such as the replacement of a sensor, the calibration of which differs slightly from that previously installed;
Tools exist to detect the occurrence of data drift, such as Evidently, or the Scipy Library whose statistical testing functions can be used for this purpose;
- an update of the data, such as a correction of the place of residence in the public profile of the user of a social network following a move;
- the evolution of techniques, which frequently demonstrates that a change of approach (use of a different AI system requiring a different data typology, for example) can bring better performance to the system, or that similar performance can be achieved with a smaller volume of data (as shown by the technique of few-shots learning, for example).
Thus, the system provider should conduct regular analysis to monitor the dataset. This analysis will be more extensive and frequent in situations where the above-mentioned causes are most likely to take place. This analysis should be based on:
- a regular comparison of data or a sample of data to source data, which can be automated;
- a regular review of data by staff trained in data protection matters, or by an ethics committee, responsible in particular for verifying that the data is still relevant and adequate for the purpose of the processing;
- a watch on the scientific literature in the field and making it possible to identify the emergence of new, more data frugal, techniques.
Data storage
The principle
Personal data cannot be stored indefinitely. The GDPR requires a period of time after which data must be deleted, or in some cases archived. This retention period must be determined by the controller according to the purpose which led to the collection of such data.
In practice
The provider must set a retention period for the data used for the development of the AI system, in accordance with the principle of storage limitation (Article 5.1.d GDPR).
Defining a retention period requires, in particular, the implementation of certain procedures described in the CNIL’s practical guide on retention periods. The CNIL notes that open source datasets are constantly evolving (by improving annotation, adding new data, purging poor quality data, etc.): a storage period of several years from the date of collection must be justified.
Set a retention period for the development phase
First, the provider of the AI system will have to set a data retention period for the use made during the development of the system. During this phase, the provider processes the data for:
- the creation of the dataset, which should be limited to strictly necessary, cleaned, pre-processed and ready to be used data for training;
- the training phase, from the first training of the AI model to the test phase to determine the characteristics and performance of the finished product. During this phase, the data must be kept securely and accessible to authorized persons only. Depending on the case, this phase can last from a few weeks to several months, or on the contrary iteratively in the case of continuous learning. This duration should be defined upstream and justified (taking into account the previous experiences of the controller, the knowledge of the duration of IT developments, the human and material resources available to carry them out, etc.).
Data storage needs to be planned upstream and monitored over time. The defined retention periods must also be applied to all concerned data, regardless of their storage medium. Compliance with retention periods can sometimes be facilitated by the use of management and governance tools to define a retentionstorage period for each data and calculate the length of time that has elapsed since the date of entry into the dataset before automatically deleting them. Particular attention must therefore be paid to the traceability of any data extracted from the main dataset and stored on third-party media, for example to enable the engineers to analyse a sample on a case-by-case basis. The measures recommended in the “Documentation” section for data traceability will facilitate the tracking of data and the expected date for deletion.
Please note:
In the case of public bodies or private bodies entrusted with a public service mission, data may also be subject to specific archiving in compliance with the obligations of the French Code du Patrimoine.
This allows the data to be permanently stored in a public archive service according to the particular interest they present. Where the public archives contain personal data, a selection shall be made to determine the data to be retained and those, which are not administratively useful or of scientific, statistical or historical interest, to be deleted.
In any event, the data retained in the context of the definitive archiving are subject to processing for archival purposes within the meaning of the GDPR and, therefore, do not fall within the scope of these how-to sheets. In addition, the data storage period must be specified in the information notice that will be brought to the attention of the data subjects.
Set a retention period for the maintenance or improvement of the product
When the data no longer have to be accessible for the day-to-day tasks related to the development of the AI system, it should in principle be deleted. However, it can be kept for product maintenance (i.e. for a later phase of performance verification or for system improvement).
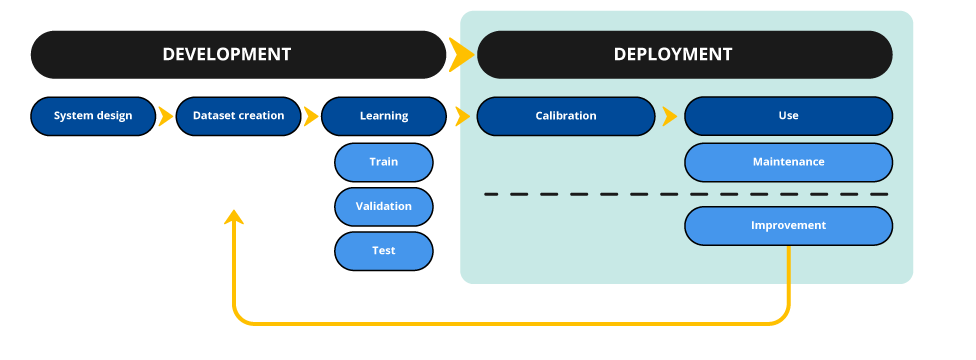
Maintenance operations
The principle of data minimisation requires keeping only the data strictly necessary for maintenance operations (by selecting the relevant data, performing pseudonymisation of the data where possible, such as blurring images for example, etc.).
These operations ensure the safety of those affected by the use of the AI system in the deployment phase, such as when the system has an effect on people, when a drop in performance could have serious consequences for people, or when it concerns the safety of a product. Thus, the storage of training data can allow audits to be carried out and facilitate the measurement of certain biases. In these cases, and where a similar result could not be achieved through the storage of general data information (such as documentation on the model proposed in the documentation section, or information on the statistical distribution of the data), prolonged data retention may be justified. However, this storage must be limited to the necessary data and should be accompanied by enhanced security measures.
Once the data has been sorted, it can be stored on a partitioned medium, i.e. physically or logically separated from the training data. This partitioning makes it possible to strengthen the security of the data and restrict its access to authorized personal only. The duration of the maintenance phase can vary from a few months to several years when the storage of this data carries little risk to people and the appropriate measures have been taken. In the case of data from open sources, the retention period provided by the data source shall be taken into account in determining the duration of the maintenance phase. However, this period must be limited and justified by a real need.
Improving the AI system
The data of the previously created dataset may also be required to improve the product resulting from the AI system thus developed. This purpose, for which a legal basis must be identified, must be brought to the attention of the data subjects, in accordance with the principle of transparency.
Specifically, only the data needed to improve the AI system can be extracted from their partitioned storage space.
Please note:
The possibility of extending the cycle by a new development or maintenance phase will not, under any circumstances, allow an indefinite extension of the retention period. An analysis of the duration necessary for the processing operations must be carried out systematically.
Security
The principle
The controller and its processors (if any) must implement appropriate technical and organisational measures to ensure a level of security appropriate to the risks (Article 32 GDPR).
The choice of measures to be implemented must take into account the state of knowledge, the costs of implementation and the nature, scope, context and purposes of the processing and the risks, the likelihood and severity of which vary, for the rights and freedoms of data subjects.
In practice
Thus, the provider of an AI system must, in particular, put into place the appropriate measures in order to secure:
- the techniques used for data collection , e.g. through encryption and robust authentication methods. It is recommended to use the means provided by the diffuser to collect data, especially when it is based on APIs. The CNIL’s recommendation on the use of APIs will then have to be applied;
- the collected data, using methods of encryption of backups, verification of their integrity, or logging of operations carried out on the dataset in accordance with the CNIL recommendation on logging measures. A frequent risk in the development of AI systems concerns duplication of data, the quality of which should be frequently analysed . Duplication of data should be limited to the extent possible and traced where unavoidable. Dedicated tools, such as NB Defense, Octopii, PiiCatcher, or techniques, such as regular expression (RegExp) search or named entity recognition for textual data, make it possible to verify the presence of personal data in certain contexts;
- the IT system used for the development of the AI system, e.g. by means of authentication methods and the training of staff with access to it, and the implementation of good IT hygiene practices;
- the IT hardware, in particular by means of methods of restricting access to premises and by analysing the guarantees provided by the data host when this is outsourced to a provider.
Security measures specific to the development and deployment phases of AI systems will be the subject of a subsequent how-to sheet. However, the recommendations and best practices traditionally implemented in IT, such as those present on the CNIL’s website, as well as the GDPR guides of the development and security team of personal data, constitute a useful reference to which the provider of the AI system can refer.
Documentation
The documentation of the data used for the development of an AI system helps ensurings the traceability requirement. It must make it possible to:
- facilitate the use of the dataset;
- demonstrate that the data were lawfully collected;
- facilitate the monitoring of data over time until it is deleted or anonymised;
- reduce the risk of unanticipated use of data;
- enable the exercise of rights for data subjects;
- identify planned or possible improvements.
In order to meet these objectives, a documentation model may be adopted, in particular where the provider uses multiple data sources or creates multiple datasets. Building on the existing models (such as those proposed by Gebru et al., 2021, Arnold et al., 2019, Bender et al., 2018, the Dataset Nutrition Label, or the technical documentation provided for in Annex IV of the AI Act), the CNIL provides below a model that can be used for this purpose, in particular where the dataset is intended to be shared. This documentation should be carried out for each dataset constituted, made available, or based on existing datasets to which a substantial changes were made. More specific documentation templates for each use case, such as the CrowdWorkSheets model, which is particularly relevant for documenting the annotation phase, may complement the proposed template.
The objectives of this documentation are to help the controller clarify its practices, to inform the users of the dataset about the conditions of its constitution and the recommendations concerning its processing, and finally, to inform people about this processing. Thus, it is recommended that this documentation be provided to users of the dataset or models it has been used to design.
It should be noted that this important documentation work can naturally feed into the data protection impact assessment (see how-to sheet 5 Carrying out an impact assessment if necessary).


