CNIL's Q&A on the Use of Generative AI Systems
Many organisations are considering deploying or using generative AI systems and are seeking guidance on the necessary measures to put in place. This Frequently Asked Questions (FAQ) offers initial answers to their queries.
Generative” artificial intelligence refers to the class of systems capable of creating content (text, computer code, images, music, audio, videos, etc.). These systems can be classified as general purpose AI systems when they can perform a whole range of tasks. This is especially true for systems based on large language models (LLMs). Designing these systems requires vast amounts of data from diverse sources (Internet, licensed third-party contents, conversations generated by human trainers, user interactions, synthetic data, etc.).
To learn more about the compliance requirements for developing these systems when they involve personal data, the CNIL provides recommendations on how to design them in compliance with the GDPR.
1. What are the benefits of generative AI?
Generative AI systems automatically generate content whose quality has recently seen significant improvements. These systems are capable of producing diverse, personalised, and realistic outputs. Essentially, generative AI can be used to perform three categories of tasks:
- Generating content from general instructions (such as images, text or computer code),
- Reprocessing existing content (such as correcting or translating texts),
- Analysing data (such as sorting or summarising documents).
The primary use of generative AI is generally intended to increase the creativity and productivity of people using it, or to be used to build other systems.
2. What are the limitations and risks of generative AI systems?
Generative models are not knowledge bases: they operate on probabilistic logic, which means that they only generate results that are statistically the most likely based on the data they were trained on. Consequently, these systems may produce inaccurate results which may, however, appear plausible (often referred to as hallucinations). This might occur when they are queried about information not included in their training data, such as events occurring after the development, since these systems are not always connected to up-to-date knowledge bases.
Overreliance on the results produced by a generative AI system without proper verification can therefore lead to erroneous decisions or incorrect conclusions.
This characteristic contributes to the so-called “black box” effect, making it difficult to understand and explain these systems. For the providers of such systems, this complicates the detection and prevention of potential biases. For users, it raises significant trust issues regarding the results provided.
Finally, the capabilities of these systems can lead to anticipatory and preventable misuse, such as disinformation through deepfakes, generation of malicious code, or information provision that permits illegal, dangerous or malicious activities (like weapon instruction).
3. What approaches are available today to use generative AI (off-the-shelf models, fine-tuning, RAG, etc.)?
The first consideration is the type of generative AI model or system to use:
- Using an off-the-shelf system or model
Whether proprietary (marketed by its supplier) or open source, an off-the-shelf system or model can be more or less generalist. It can therefore be more or less adapted to specific tasks. In some cases, it can be directed to a specific task or context, e.g. through pre-prompt instructions, before generating the main response. These instructions can be integrated into the system or provided by the user, and do not require specific resources.
or
- Developing its own generative AI model
Alternatively, it is possible not to use a pre-trained AI model but to train its own model before integrating it into the system. Currently, only a very limited number of entities can undertake this due to the substantial resources and skills required.
Then, regardless of the type of model or system chosen, its performance can be improved using the following methods:
- Connecting the system to a knowledge base (RAG)
Retrieval Augmented Generation (RAG) integrates an information retrieval mechanism into a vectorised database (embedding). This enables producing outputs enriched by external data that are potentially more specific and easier to update than the model itself. While this method requires more resources and skills than using simple off-the-shelf systems or models, it offers better adaptability and traceability of the information contained in the answers.
and/or
- fine-tuning a pre-trained model to specific data
Fine tuning involves changing the parameters (weights) of a model while maintaining its core architecture (e.g. that of a large language model pre-trained in some languages). This method enhances performance for specific domain or queries. However, it demands significant resources, particularly in terms of computing capacity.
4. How to choose your generative AI system?
It is recommended to start from concrete needs to choose the most suitable system, and to consider the risks involved, based on the intended uses, but also on limitations of the system envisaged. For example, facilitating the writing of certain content by making a conversational agent available to its employees will be less risky than using a system to assist decision making about customers, candidates or citizens. The system, the chosen method, and the kind of deployment should therefore be subject to a higher level of requirements in the latter case.
Depending on the intended use and its sensitivity, it is necessary to check:
- Its general safety and security, e.g. ensuring that the tool is developed to deny responses to malicious, toxic or unlawful queries;
- Its relevance to the specifically identified need, for example by favouring systems limiting hallucinations, citing their sources, filtering outputs, or trained or fine-tuned on a quality and specific dataset;
- Its robustness, for example by relying on systems already tested and proven for the intended tasks;
- The absence of potential biases, e.g. discriminatory biases that could result in particular from a lack of diversity of training data;
- Its compliance with the applicable rules, taking note of its licence to use or information on training data, whether proprietary or open source.
The easiest way to do this is usually to access the system documentation and to request external evaluations if required. In the latter case, if necessary and feasible, it may be appropriate to conduct or commission a tailor-made evaluation for the intended use.
5. Which deployment method should be preferred (on premise, API, cloud)?
Generative AI systems can be delivered on-premise, on a hosted cloud infrastructure or on-demand via Application Programming Interfaces (APIs). The choice of a deployment mode depends on the use case and the input data.
For non-confidential uses, relying on a consumer service to which access is permitted through dedicated business e-mail addresses may be considered with appropriate safeguards (provided that account creation with personal e-mail addresses is avoided and, where appropriate, the possibility for the system provider to reuse usage data is disabled).
If the intended use consists in providing personal data (e.g. customer or employee data) or sensitive or strategic documentation (e.g. for RAG), it generally seems more appropriate and secure to favour the deployment of on-premise solutions which limits the risks of data extraction from a third party (in particular as detailed in ANSSI’s security recommendations for a generative AI system).
However, given the cost of setting up and operating an on-premise system, it will often be easier to use a system hosted in a remote infrastructure (cloud or off-premise). In this case, it will be necessary to secure the use of external infrastructures through a contract with the system host and, where applicable, with the AI system provider. This contract must clearly specify the scope of responsibility and authorised access to the data processed. In this regard, there is nothing to prevent small companies or local authorities with limited resources from using a shared infrastructure, provided that data transfers are supervised and their security is ensured
In addition, if the personal data may be transferred outside the European Union (for example because the hosting infrastructure is located outside the EU or is operated by a non-European provider), the user entity must, in addition, supervise the processing of their recipient.
Finally, if using a system through APIs is considered, it must be pointed out that the control of the system is then almost exclusively in the hands of its supplier. Therefore, particular attention should be paid to the data submitted to the AI system, avoiding as far as possible inputs containing personal data. Particular attention should also be paid to contractual conditions, especially to issues of data transfers outside the EU.
6. How should a generative AI system be implemented and managed?
Prior risk analysis and clear governance strategies must be considered before implementing this type of system. In particular, the deployer must ensure their compliance with the GDPR.
Regardless of the intended usage, the deployer must particularly:
- Question its role and the role of the provider with regard to the processing of personal data, by entering into a contract or a joint liability agreement with the latter if necessary, or even by supervising the transfer of data outside the European Union as mentioned above;
- Ensure the security of the data it provides for the development of the system (e.g. for a tailor-made or fine-tuned model) or during the deployment of the system (e.g. by deciding to object to the reuse of usage data by the system provider, or even the recording of history).
For more information: see ANSSI’s security recommendations for a generative AI system.
More generally, it is recommended to regulate the use of a generative AI system through internal policies or charters, clearly defining the authorised and prohibited uses.
Depending on the deployment method, it will be necessary to prohibit the provision of certain confidential (e.g. covered by industrial and commercial secrecy) or personal data.
For example, where the data is likely to be reused by the provider (in accordance with its terms and conditions), the organisation deploying the system will have to conduct a case-by-case analysis to determine whether or not it should prohibit the provision of any personal data, or only certain categories.
Conversely, such prohibitions are unnecessary for on-premise deployment where data re-use by the provider is not feasible.
An intermediate case may be to allow users to provide freely accessible data to such systems. However, the re-use of such freely accessible data by the AI system provider will not always be possible. The latter will have to conduct a dedicated analysis.
In addition to the need for intelligibility and accessibility of these documents, it is recommended to train users appropriately and to carry out regular checks.
7. How can end-users of these systems be trained and made aware of the risks?
In the general case, the organisation deploying the system will bear the legal liability in case of misuse of AI by its staff. It is therefore recommended to familiarise end-users with the functioning and limitations of these systems (how outputs are produced, possible data transfers, etc.), as well as authorised and prohibited uses.
End-users should be made accountable for their use of these tools by encouraging them to verify input data and output quality (e.g. through mandatory training prior to the use of these systems).
End-users should only submit information that they are allowed to share in the prompt or input data. For example, they should never share confidential information such as personal data, company or administrative data (especially when covered by a secret such as business secrecy or ethical obligations) when using a consumer service. The organisation could even provide input templates or pre-prompt directly accessible in the tool to encourage end-users to perform well-identified and proven tasks.
With regard to outputs generated by the system, end-users should always approach them critically and verify that:
- they are accurate or of good quality (especially in the absence of sources, e.g. through counterfactual research);
- it is not plagiarism (e.g. in case of high suspicion of regurgitation of a protected work, trying to find the initial source);
- that they do not introduce biases that could lead to discrimination (for example, by reproducing a stereotype).
Finally, they should be alerted on the risk of loss of confidence or competence associated with excessive use of the system (also known as automation bias). In order to avoid any loss of human control, it is a good practice to never reproduce the outputs of these systems as such, including when they incorporate filters that are supposed to prevent the generation of inappropriate content (since these systems are never flawless).
In this regard, integrating generative AI bricks into an information system (IS) should be designed to clearly inform users of the origin of the proposal, reminding them that it is up to them not to take the proposal “as is”. For example, the system can provide at least two answers for each question, allowing the human operator to select the relevant elements of each answer to consolidate its own.
8. What governance should be implemented for these systems?
Data Protection Officers (DPO) can play a useful role in this regard as they are already tasked with data protection issues related to these systems, if necessary in collaboration with chief information security officers (CISO).
They can also serve as point of contact for end-users to raise ethical concerns or difficulties. If issues are justified, the designated individual should be able to alert the organization about risks that may necessitate system adjustments or request changes from the provider, especially if only the provider can implement them
Depending on the sensitivity of the usage, it may also be appropriate to consider regular checks to ensure that the recommended rules and best practices are complied with. In any case, in the first months and years of the use of the generative AI system, it is recommended to regularly gather the opinion of end-users on the usefulness and limitations. This investigation may also be extended to anyone who may be affected by its use.
Finally, in cases of particularly sensitive uses, it is recommended that consideration be given to setting up an ethics committee or appointing a delegated point of contact to ensure compliance with the rules and best practices identified. Indeed, having an external perspective from operational teams can help identify risks that might otherwise be overlooked or minimised (such as bias or adverse effects). This committee or delegated point of contact should give a formal opinion before the deployment of the AI system or of a new use, and be regularly informed, for example through an annual review.
9. How to ensure that the use of a generative AI system complies with the GDPR?
As regards GDPR compliance, the CNIL has issued recommendations on the creation of datasetsand training of AI systems. Since most generative AI systems have been developed using personal data, it is your responsibility, as a user or integrator, to ask the provider about the compliance of its system with the GDPR and these recommendations.
These recommendations also apply to any AI system deployer that would process personal data in the context of its development, maintenance or improvement.
For example, they apply to:
- the deployer fine-tuning the system with its own data, who will then become data controller, as well as a provider under the AI Regulation, but only for that fine-tuning stage;
- the deployer choosing to connect the system to its own knowledge base (RAG) who will also be responsible for this processing when it contains personal data.
Further recommendations will be published in the coming months by the CNIL. Pending their publication, it is recommended to involve the Data Protection Officer (DPO) and, where appropriate, to carry out a Data Protection Impact Assessment (DPIA).
10. How to ensure compliance of the use of a generative AI system with the European AI Act?
The EU AI Act enters into force on 1 August 2024. It focuses on the risks that AI systems pose to health, safety and fundamental rights. The AI Act classifies the systems into four levels of risk by establishing different rules for each of them (ranging from outright prohibition to transparency requirements).
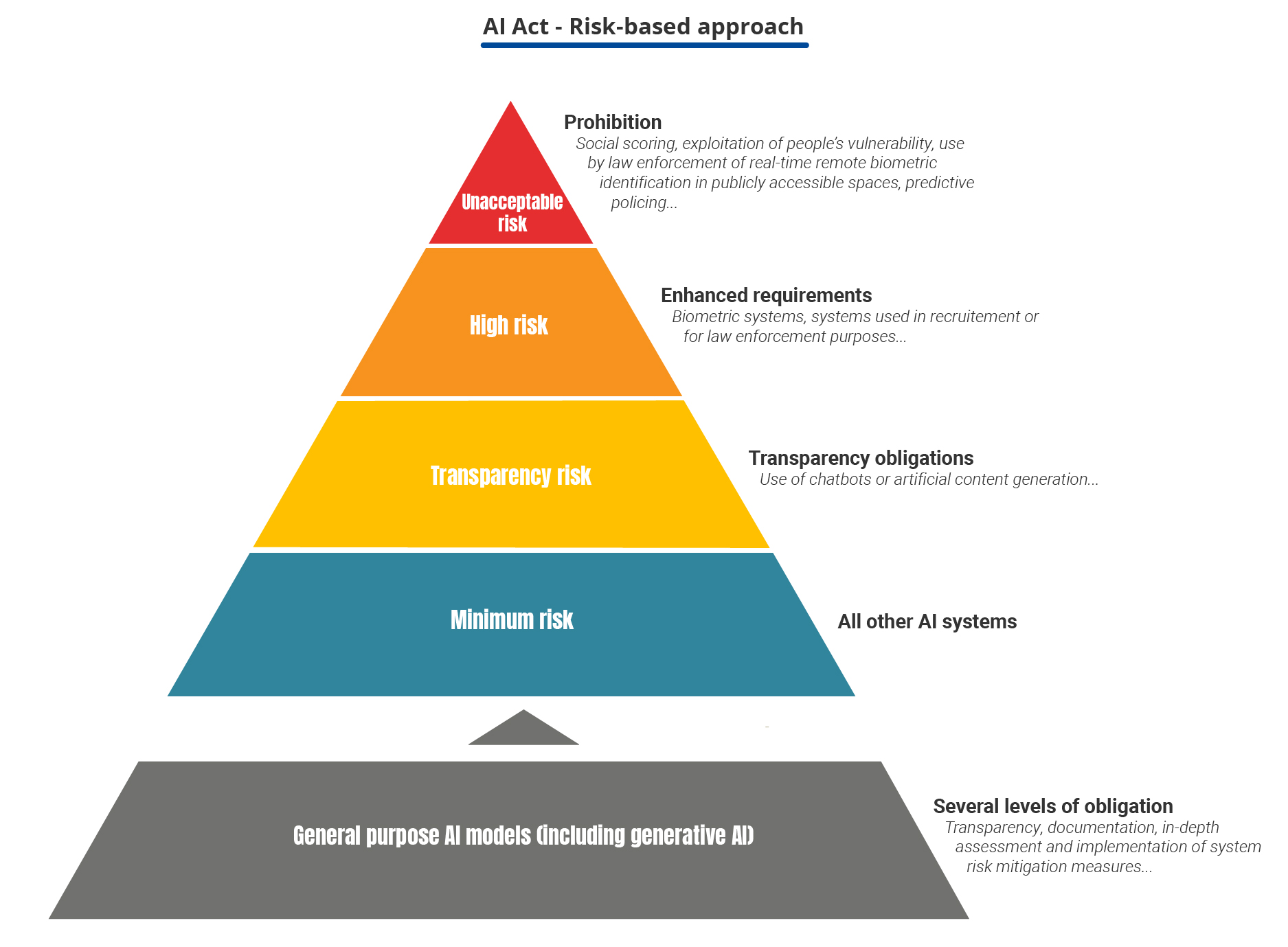
The use of generative AI systems, when not integrated into a high-risk system (which would otherwise be subject to additional requirements), is framed under general purpose AI systems justifying increased transparency requirements (Chapter IV), as well as the underlying models under general purpose AI models (Chapter V).
The AI Act provides, inter alia, that organisations deploying these systems must be transparent with users about such use. Systems designed to act directly with people must therefore be developed in such a way that people are informed that they are interacting with an AI system. Users of these systems must inform the public that the images, video, text, etc.ir they publish, have been generated by this means.

